
In our last blog, we talked about how configuration changes are the root cause of most incidents. Being unaware of those configuration changes slows our ability to understand and fix incidents. We used the example of a patient visiting his doctor. If the doctor is unaware of changes to the patient since his last visit, the doctor will take longer to find out what the problem is. This takes away valuable time from the doctor and prolongs the patients’ illness.
But change needs to happen. To maintain. To improve. To compete. Let’s continue with our doctor/patient analogy. Let’s say the patient (me) embarks on an intermittent fasting program to lose weight. This is a change, and ideally it’s a positive change. Now, a person could take the time and effort to research “intermittent fasting”, the myriad types of fasting, and then come up with a detailed plan of action with meal plans, exercise regimen, and a proactive estimate of weight loss across the weeks, months, or year.
The problem is, most people don’t do that. Most people don’t have the time, energy, or motivation. Like me, people look at their friends and decide… hey it worked for them, maybe I can do that too. They jump right in without much planning or thought about the consequences, other than the intended successful weight loss. Clearly, with hindsight, you can see the loopholes and dangers of this casually adopted process. Now I’m not suggesting businesses run with such an ad hoc process, but it must be noted that business is composed of people like me, who favor the path of least resistance, to put it kindly. Let’s take a closer look.
In the realm of infrastructure management, Communication Service Providers (CSP) must deal with change on a constant basis. Change improves products and services, but how one manages the change is critical to the overall operational success of the organization. Due to its critical nature, CSP has dedicated teams responsible for planning and implementing network and service changes. The change request (CR) is pre-planned and ideally goes through a review process detailing information on what the change involves, the required steps to be performed, the affected devices, and the planned maintenance window or timeframe. Once approved, the changes are made to the infrastructure.
So far, so good…until the change request is simply rubber-stamped by someone like me, because I don’t have the time, energy, or resources to properly plan and prognosticate the cause and effect outcomes of impending change requests. Mind you, in my defense, there can be many CRs occurring throughout the day or even simultaneously, depending on the size and nature of the enterprise, so even the most diligent, conscientious change team wouldn’t be able to effectively predict change outcomes. Even in post mortem, change teams find it too time-consuming to trace back changes and note down resulting configuration updates made to the infrastructure. So typically, a post-implementation review happens only when something has gone wrong. During an incident or outage, this is a valuable loss of time and often involves multiple teams and groups jumping on bridge calls to figure out what is going on, and who is the culprit. So essentially the change management process is more often than not, a two-step version of rubber stamping, and crossing fingers…and dealing with the fallout after it occurs.
Not unlike my adventures into intermittent fasting, CSP’s assume the configuration changes made by the CRs are correct. Worse yet, sometimes technicians bypass the CR process altogether by simply making ad-hoc changes in the interest of saving time, or due to the task being “Just a simple change.” Either way, the unplanned changes will result in errors and outages, while the remedial tasks become all the more challenging in larger environments where change occurs frequently.
Returning to my experiences as an intermittent faster, I decided my blood thinning medication was not really needed since I was fasting, on a whim, I discontinued taking them. Eventually, I started feeling unwell and went to the physician. Now imagine what would happen if I withheld informing my doctor of these recent changes to my diet and medication regimen? If he were unaware of my newfound fasting hobby and unaware that I had set aside my blood-thinning medication, he would be limited to guessing what was ailing me based on my symptoms and tests performed. This disparity or gap in change awareness is what we refer to as the Change Knowledge Gap. In infrastructure operations, the Change Knowledge Gap is the lack of visibility to infrastructure configuration change between those making the changes, and those left dealing with the impact of those changes, namely incidents and outages.
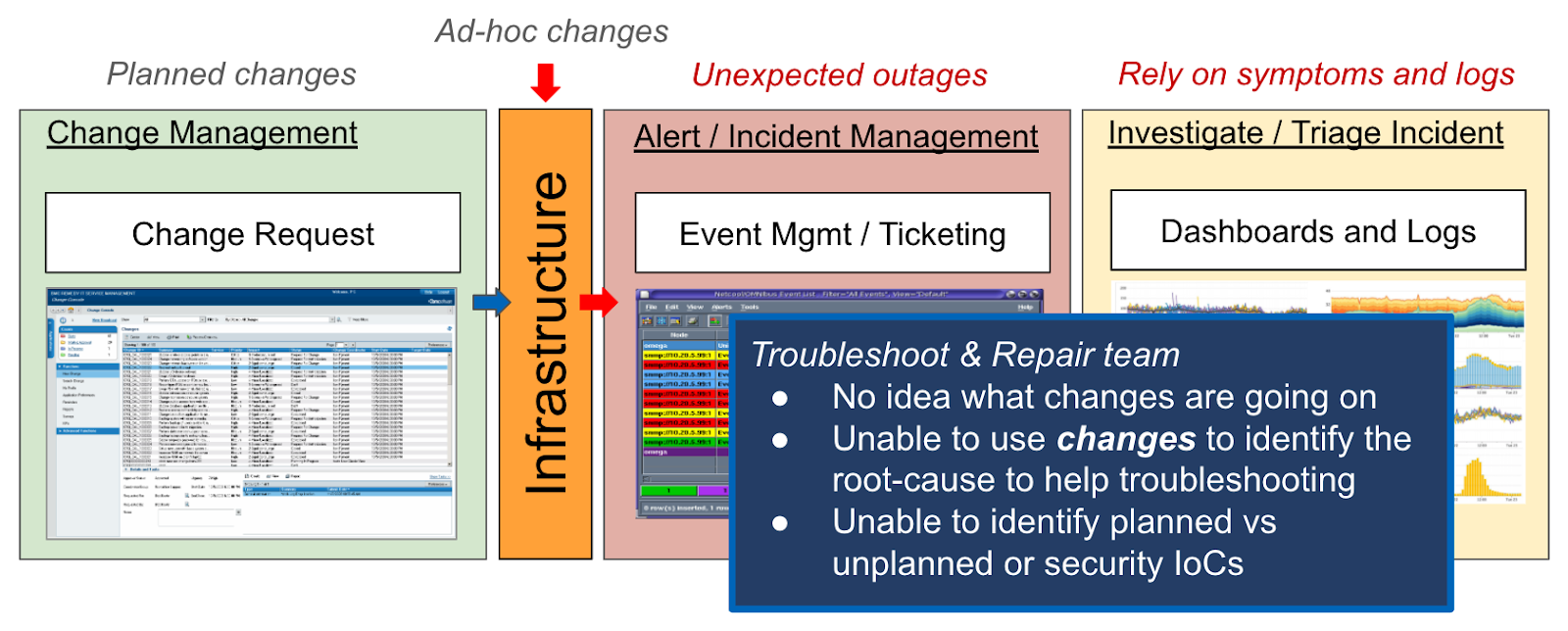
The Change Knowledge Gap is not necessarily the death knell of infrastructure operations. My physician had many tools at his disposal to ultimately test and understand that my blood pressure had returned to elevated heights. Similarly, today’s CR monitoring team has plenty of instrumentation and telemetry to diagnose the health of the infrastructure. They have alert monitoring systems that let the team know as soon as something goes wrong. They have performance monitoring with anomaly detection to help predict potential problems in the future. They have application service and network topology with correlation, to help suppress unrelated events. They have log analytics to help dive into the detailed logs, to try to piece the puzzle from the bottom up. And more recently they have AI to help reduce the noise from all of the information.
So yes. I’m covered, and business is covered. We can eventually find out what the problem is. However, if my doctor had asked a very simple question, he could have saved a lot of time, money, frustration, and maybe even my health, to get to the root of my wrongs. If he had access to the question, “What has changed from the last time?” it would have been the starting point of the diagnosis. In business, it’s the same. The question that is lacking, is the most simple and yet the most profound… “What the #%&$ changed?!?” Being able to quickly and efficiently answer this question, is the monitoring team’s key to triaging and identifying the root cause of an incident or outage. And of course, to do so, the team needs visibility to the configuration changes made to the affected services and devices. From that starting point, the team can search for other changes, not directly related to the incident, yet collaterally impacted by the incident. This bridging, or ideally elimination, of the operations change gap, allows a team to see and quickly and efficiently fix how a configuration change brought on by a completed change request, can impact the services. In turn, eventually, this creates the rudimentary steps of a proactive platform where monitoring teams will have greater visibility to the root causes, instead of the symptoms of complex outages, or incidents. In other words, having “change awareness” is a strategic component to the process in preventing and remediating incidents.
SIFF encourages “All Configs. Searchable. In One Place,” pushing the boundaries beyond other configuration management tools. Traditional configuration management tools are focused on applying configuration changes, SIFF is uniquely designed to collect all configuration data from all sources, to help troubleshoot and identify related changes that can be the root cause of incidents.
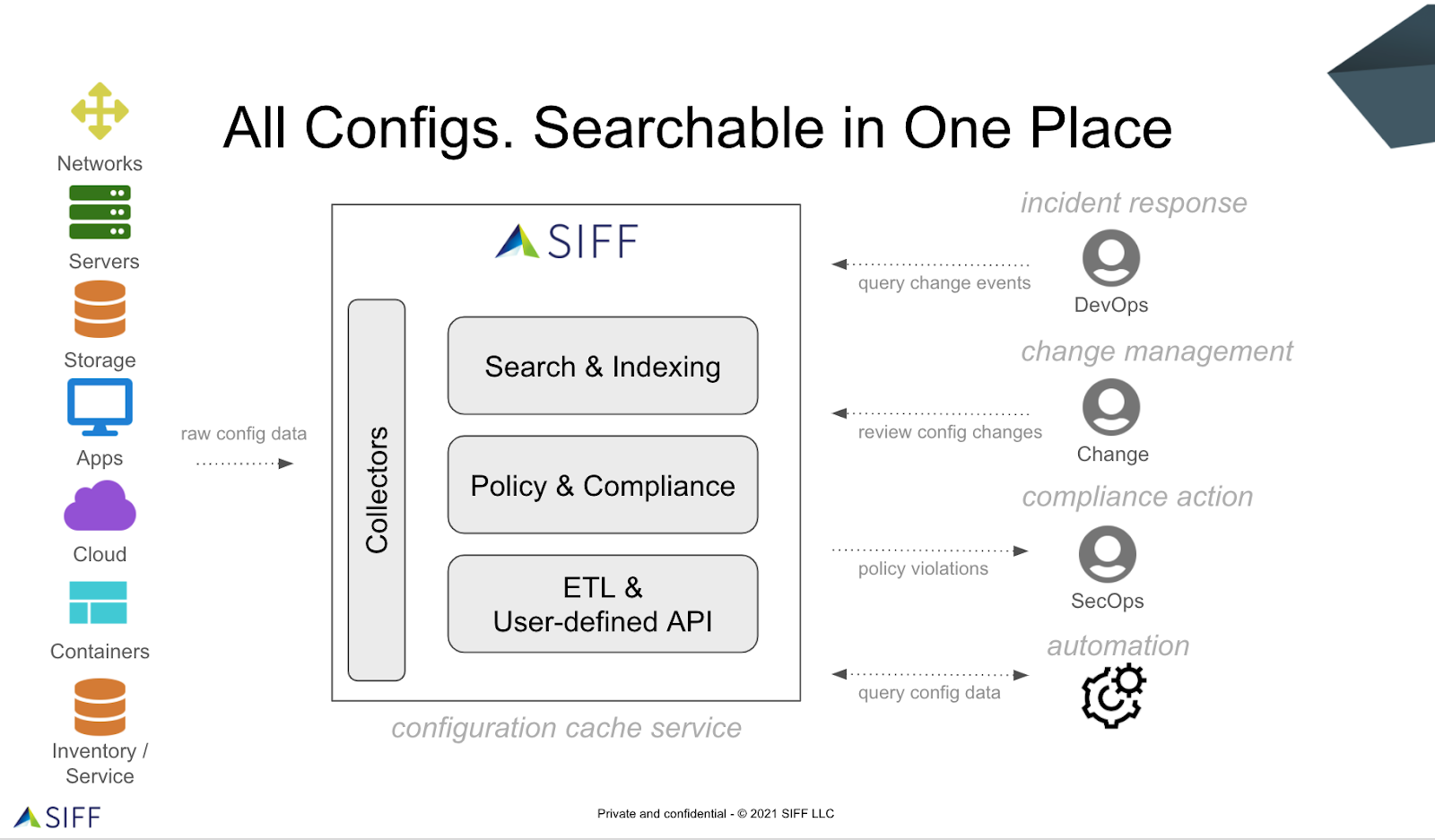
To find out more about how SIFF:
- Troubleshoots complex outages by identifying config changes related to the incident
- Reduces and prevents incidents by improving the change process
- Continuously analyzes configuration for policy compliance and governance
Learn more about SIFF.